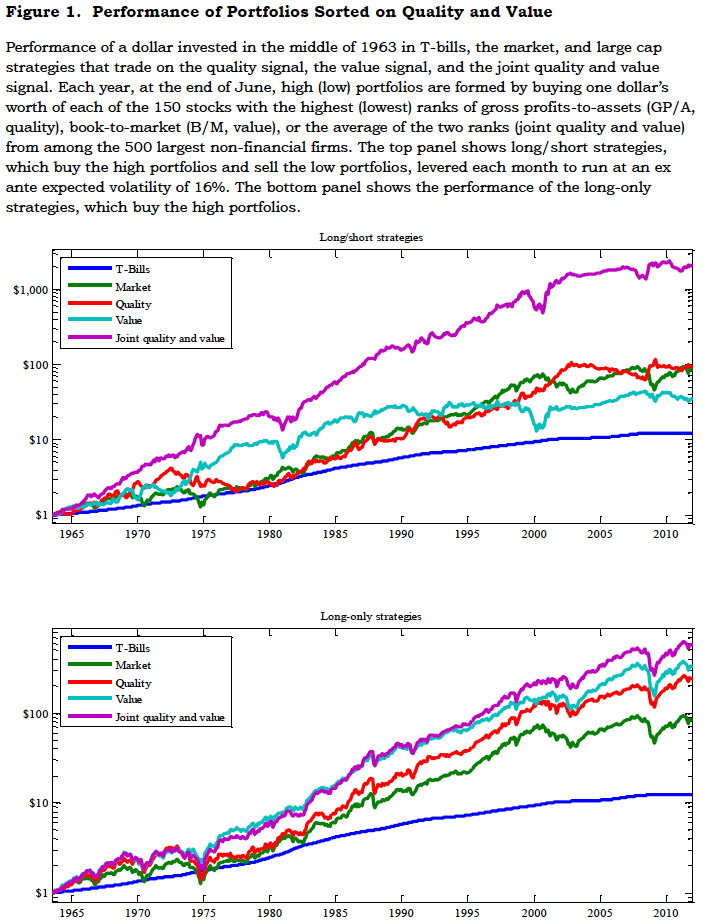
Two recent articles, Was Benjamin Graham Skillful or Lucky? (WSJ), and Ben Graham’s 60-Year-Old Strategy Still Winning Big (Forbes), have thrown the spotlight back on Benjamin Graham’s investment strategy and his record. In the context of Michael Mauboussin’s new book The Success Equation, Jason Zweig asks in his WSJ Total Return column whether Graham was lucky or skillful, noting that Graham admitted he had his fair share of luck:
We tend to think of the greatest investors – say, Peter Lynch, George Soros, John Templeton, Warren Buffett, Benjamin Graham – as being mostly or entirely skillful.
Graham, of course, was the founder of security analysis as a profession, Buffett’s professor and first boss, and the author of the classic book The Intelligent Investor. He is universally regarded as one of the best investors of the 20th century.
But Graham, who outperformed the stock market by an annual average of at least 2.5 percentage points for more than two decades, coyly admitted that much of his remarkable track record may have been due to luck.
John Reese, in his Forbes’ Intelligent Investing column, notes that Graham’s Defensive Investor strategy has continued to outpace the market over the last decade:
Known as the “Father of Value Investing”—and the mentor of Warren Buffett—Graham’s investment firm posted annualized returns of about 20% from 1936 to 1956, far outpacing the 12.2% average return for the broader market over that time.
But the success of Graham’s approach goes far beyond even that lengthy period. For nearly a decade, I have been tracking a portfolio of stocks picked using my Graham-inspired Guru Strategy, which is based on the “Defensive Investor” criteria that Graham laid out in his 1949 classic, The Intelligent Investor. And, since its inception, the portfolio has returned 224.3% (13.3% annualized) vs. 43.0% (3.9% annualized) for the S&P 500.
Even with all of the fiscal cliff and European debt drama in 2012, the Graham-based portfolio has had a particularly good year. While the S&P 500 has notched a solid 13.7% gain (all performance figures through Dec. 17), the Graham portfolio is up more than twice that, gaining 28.5%.
Reese’s experiment might suggest that Graham is more skillful than lucky.
In our recently released book, Quantitative Value: A Practitioner’s Guide to Automating Intelligent Investment and Eliminating Behavioral Errors, Wes and I examine one of Graham’s simple strategies in the period after he described it to the present day. Graham gave an interview to the Financial Analysts Journal in 1976, some 40 year after the publication of Security Analysis. He was asked whether he still selected stocks by carefully studying individual issues, and responded:
I am no longer an advocate of elaborate techniques of security analysis in order to find superior value opportunities. This was a rewarding activity, say, 40 years ago, when our textbook “Graham and Dodd” was first published; but the situation has changed a great deal since then. In the old days any well-trained security analyst could do a good professional job of selecting undervalued issues through detailed studies; but in the light of the enormous amount of research now being carried on, I doubt whether in most cases such extensive efforts will generate sufficiently superior selections to justify their cost. To that very limited extent I’m on the side of the “efficient market” school of thought now generally accepted by the professors.
Instead, Graham proposed a highly simplified approach that relied for its results on the performance of the portfolio as a whole rather than on the selection of individual issues. Graham believed that such an approach “[combined] the three virtues of sound logic, simplicity of application, and an extraordinarily good performance record.”
Graham said of his simplified value investment strategy:
What’s needed is, first, a definite rule for purchasing which indicates a priori that you’re acquiring stocks for less than they’re worth. Second, you have to operate with a large enough number of stocks to make the approach effective. And finally you need a very definite guideline for selling.
What did Graham believe was the simplest way to select value stocks? He recommended that an investor create a portfolio of a minimum of 30 stocks meeting specific price-to-earnings criteria (below 10) and specific debt-to-equity criteria (below 50 percent) to give the “best odds statistically,” and then hold those stocks until they had returned 50 percent, or, if a stock hadn’t met that return objective by the “end of the second calendar year from the time of purchase, sell it regardless of price.”
Graham said that his research suggested that this formula returned approximately 15 percent per year over the preceding 50 years. He cautioned, however, that an investor should not expect 15 percent every year. The minimum period of time to determine the likely performance of the strategy was five years.
Graham’s simple strategy sounds almost too good to be true. Sure, this approach worked in the 50 years prior to 1976, but how has it performed in the age of the personal computer and the Internet, where computing power is a commodity, and access to comprehensive financial information is as close as the browser? We decided to find out. Like Graham, Wes and I used a price-to-earnings ratio cutoff of 10, and we included only stocks with a debt-to-equity ratio of less than 50 percent. We also apply his trading rules, selling a stock if it returned 50 percent or had been held in the portfolio for two years.
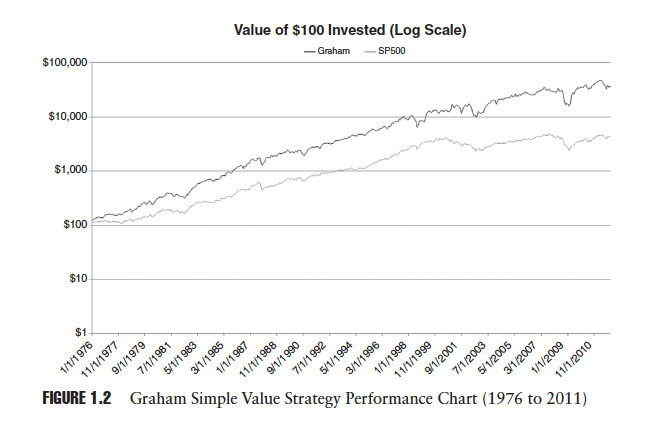
Figure 1.2 below taken from our book shows the cumulative performance of Graham’s simple value strategy plotted against the performance of the S&P 500 for the period 1976 to 2011:
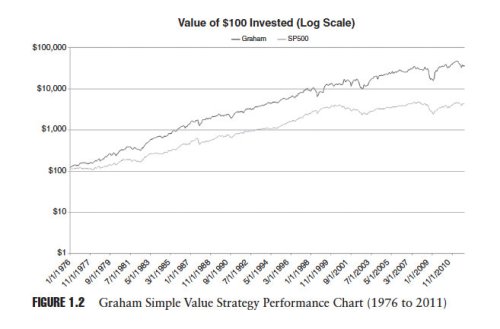
Amazingly, Graham’s simple value strategy has continued to outperform.
Table 1.2 presents the results from our study of the simple Graham value strategy:
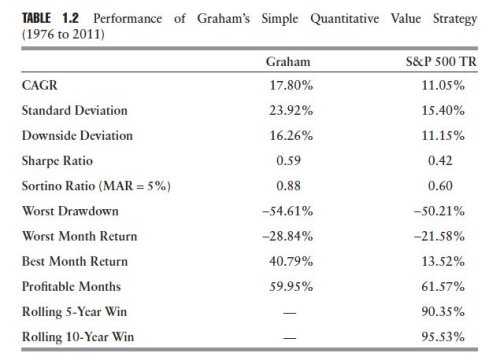
Graham’s strategy turns $100 invested on January 1, 1976, into $36,354 by December 31, 2011, which represents an average yearly compound rate of return of 17.80 percent—outperforming even Graham’s estimate of approximately 15 percent per year. This compares favorably with the performance of the S&P 500 over the same period, which would have turned $100 invested on January 1, 1976, into $4,351 by December 31, 2011, an average yearly compound rate of return of 11.05 percent. The performance of the Graham strategy is attended by very high volatility, 23.92 percent versus 15.40 percent for the total return on the S&P 500.
The evidence suggests that Graham’s simplified approach to value investment continues to outperform the market. I think it’s a reasonable argument for skill on the part of Graham.
It’s useful to consider why Graham’s simple strategy continues to outperform. At a superficial level, it’s clear that some proxy for price—like a P/E ratio below 10—combined with some proxy for quality—like a debt-to-equity ratio below 50 percent—is predictive of future returns. But is something else at work here that might provide us with a deeper understanding of the reasons for the strategy’s success? Is there some other reason for its outperformance beyond simple awareness of the strategy? We think so.
Graham’s simple value strategy has concrete rules that have been applied consistently in our study. Even through the years when the strategy underperformed the market our study assumed that we continued to apply it, regardless of how discouraged or scared we might have felt had we actually used it during the periods when it underperformed the market. Is it possible that the very consistency of the strategy is an important reason for its success? We believe so. A value investment strategy might provide an edge, but some other element is required to fully exploit that advantage.
Warren Buffett and Charlie Munger believe that the missing ingredient is temperament. Says Buffett, “Success in investing doesn’t correlate with IQ once you’re above the level of 125. Once you have ordinary intelligence, what you need is the temperament to control the urges that get other people into trouble in investing.”
Was Graham skillful or lucky? Yes. Does the fact that he was lucky detract from his extraordinary skill? No because he purposefully concentrated on the undervalued tranch of stocks that provide asymmetric outcomes: good luck in the fortunes of his holdings helped his portfolio disproportionately on the upside, and bad luck didn’t hurt his portfolio much on the downside. That, in my opinion, is strong evidence of skill.
Buy my book The Acquirer’s Multiple: How the Billionaire Contrarians of Deep Value Beat the Market from on Kindle, paperback, and Audible.
Here’s your book for the fall if you’re on global Wall Street. Tobias Carlisle has hit a home run deep over left field. It’s an incredibly smart, dense, 213 pages on how to not lose money in the market. It’s your Autumn smart read. –Tom Keene, Bloomberg’s Editor-At-Large, Bloomberg Surveillance, September 9, 2014.
Click here if you’d like to read more on The Acquirer’s Multiple, or connect with me on Twitter, LinkedIn or Facebook. Check out the best deep value stocks in the largest 1000 names for free on the deep value stock screener at The Acquirer’s Multiple®.
Read Full Post »